What is Data Annotation?
Data Annotation (some time also called as data labeling) is the process of defining ground truth in unstructured data such as images. Think of ground truth as the gold standard (as defined by humans for AI/ML to mimic), which defines the objective an AI/ML model needs to meet.
For example, if you want to train an ML model to detect cars, you need to annotate or label many car images, accounting for most possible variations (Sedans, Compacts, SUVs, colors, shapes, age etc.) in the real world, so that a machine can construct a model of how cars look.
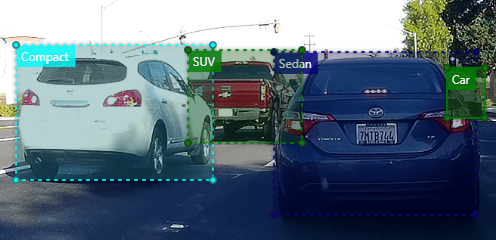
In this short article, we will explore data annotations in the context of an enterprise scale AI development and deployment.
What’s the big deal about it
Building AI/ML models typically needs hundreds or thousands of ground truth examples to train the model. Of course, the actual training volume needs depend on the task complexity, ML algorithm, real world data variability and collect-ability.
As a result, from a work coordination and execution stand point, annotating data is generally one of the most complex and time consuming part of the whole AI building and improvement process.
In my experience, the total time and effort data annotations take is typically 20-40% of the overall effort in developing AI. Any enterprise that wants to do AI at scale has to think about addressing this crucial step.
How is it typically done
Classifying or labeling objects of interest within an image takes painstaking diligence. Annotations in many cases are done by data scientists, sometimes assisted by a closed group of individuals. At the other end is a crowd-sourced model such as Mechanical Turk, which might need a closed group of experts to initially seed the process with the right content and examples, so that scalers (people who scale up the work) can pick up the slack.
Once desired volume of data is annotated, data scientists who oversee the whole process, will use these annotations to train the models. During the training some additional annotations to tighten up the model learning might be needed. Finally, once the model is in production, the continuous learning process might need some more data annotations to regulate the desired performance. Thus data annotations is not a one time work, but has relevance through out the AI life cycle.
There are several tools in the market that support the above described data annotation process, be it one-person labeling or true crowd sourced labeling. Some of the popular options are: Amazon Mechanical Turk, Label Box, Microsoft VoTT, MIT LabelMe, Google’s AutoML Labeling etc.
Choosing your data annotation Platform
For a sustainable and efficient enterprise AI development, firstly it is important to move away from an annotation tool mindset to an annotation platform mindset.
A data annotation platform, in addition to the annotation functionality, includes workflow, marketplace, guardrails/governance and controls for an enterprise use. For example, the platform should be able to support multiple data scientists, annotators, and projects simultaneously.
The following are some of the most important aspects when choosing a data annotation platform.
- Process: A structured, repeatable, and reliable data annotation workflow
- Scale: Ability to have multiple users annotate in a consistent, collaborative and coordinated manner; Crowd source-ability.
- Data: Ability to annotate various types of data such as imagery (includes RGB, LiDAR, Infrared, 3D MRIs, etc.), video (360, HD/8K, aerial, ground), audio (stereo, mono, surround etc), text (language, orientation etc.)
- Annotations: Ability to support various annotation techniques such as, bounding boxes, polygons, masks, or pixel based annotations – semantic segmentation etc. for imagery.
- Integrations: Annotate once and publish in many different formats for data scientists to use (e.g., TF Record, COCO, Pascal VOC etc.)
- Security: Ability to secure your data and annotations. e.g., limit and restrict who can see your images and annotations. Control over your data and annotations. Grant/Revoke access.
- Manage and Support: Ability to manage annotation data either batch or trickle feed – typically as a feedback to improve models; Implement new features as needed (modular architecture)
- Isolate: Ability to isolate projects by scope, purpose or other considerations; e.g., making projects as public or private.
- Asset-ize: Architectural flexibility to license your data and annotations to vendors, partners or researchers
- Incentive: Ability to attract and reward annotators as annotation is a very monotonous job
Why a custom one makes sense
Given the above requirements, most options available in the market, which are either commercial off the shelf or open source do not make it to the shortlist. While they have strength in some aspects, they completely miss the mark on the others.
Therefore, It makes more sense to build an annotation platform for your own purpose. The high barrier for custom development can be circumvented through customizing or extending an open source implementation such as Microsoft VoTT.
Stay tuned to the next article to learn more about how to go about building your own enterprise scale data annotation platform.

Leave a comment